 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDexFormer: Cross-Embodied Dexterous Manipulation via History-Conditioned Transformer
Feb 09, 2026Dexterous manipulation remains one of the most challenging problems in robotics, requiring coherent control of high-DoF hands and arms under complex, contact-rich dynamics. A major barrier is embodiment variability: different dexterous hands exhibit distinct kinematics and dynamics, forcing prior methods to train separate policies or rely on shared action spaces with per-embodiment decoder heads. We present DexFormer, an end-to-end, dynamics-aware cross-embodiment policy built on a modified transformer backbone that conditions on historical observations. By using temporal context to infer morphology and dynamics on the fly, DexFormer adapts to diverse hand configurations and produces embodiment-appropriate control actions. Trained over a variety of procedurally generated dexterous-hand assets, DexFormer acquires a generalizable manipulation prior and exhibits strong zero-shot transfer to Leap Hand, Allegro Hand, and Rapid Hand. Our results show that a single policy can generalize across heterogeneous hand embodiments, establishing a scalable foundation for cross-embodiment dexterous manipulation. Project website: https://davidlxu.github.io/DexFormer-web/.
Learning Generalizable Hand-Object Tracking from Synthetic Demonstrations
Dec 22, 2025We present a system for learning generalizable hand-object tracking controllers purely from synthetic data, without requiring any human demonstrations. Our approach makes two key contributions: (1) HOP, a Hand-Object Planner, which can synthesize diverse hand-object trajectories; and (2) HOT, a Hand-Object Tracker that bridges synthetic-to-physical transfer through reinforcement learning and interaction imitation learning, delivering a generalizable controller conditioned on target hand-object states. Our method extends to diverse object shapes and hand morphologies. Through extensive evaluations, we show that our approach enables dexterous hands to track challenging, long-horizon sequences including object re-arrangement and agile in-hand reorientation. These results represent a significant step toward scalable foundation controllers for manipulation that can learn entirely from synthetic data, breaking the data bottleneck that has long constrained progress in dexterous manipulation.
DexFlow: A Unified Approach for Dexterous Hand Pose Retargeting and Interaction
May 02, 2025Despite advances in hand-object interaction modeling, generating realistic dexterous manipulation data for robotic hands remains a challenge. Retargeting methods often suffer from low accuracy and fail to account for hand-object interactions, leading to artifacts like interpenetration. Generative methods, lacking human hand priors, produce limited and unnatural poses. We propose a data transformation pipeline that combines human hand and object data from multiple sources for high-precision retargeting. Our approach uses a differential loss constraint to ensure temporal consistency and generates contact maps to refine hand-object interactions. Experiments show our method significantly improves pose accuracy, naturalness, and diversity, providing a robust solution for hand-object interaction modeling.
TelePhantom: A User-Friendly Teleoperation System with Virtual Assistance for Enhanced Effectiveness
Dec 18, 2024



Dexterous manipulation is a critical area of robotics. In this field, teleoperation faces three key challenges: user-friendliness for novices, safety assurance, and transferability across different platforms. While collecting real robot dexterous manipulation data by teleoperation to train robots has shown impressive results on diverse tasks, due to the morphological differences between human and robot hands, it is not only hard for new users to understand the action mapping but also raises potential safety concerns during operation. To address these limitations, we introduce TelePhantom. This teleoperation system offers real-time visual feedback on robot actions based on human user inputs, with a total hardware cost of less than $1,000. TelePhantom allows the user to see a virtual robot that represents the outcome of the user's next movement. By enabling flexible switching between command visualization and actual execution, this system helps new users learn how to demonstrate quickly and safely. We demonstrate its superiority over other teleoperation systems across five tasks, emphasize its ease of use, and highlight its ease of deployment across diverse input sensors and robotic platforms. We will release our code and a deployment document on our website: https://telephantom.github.io/.
A Compacted Structure for Cross-domain learning on Monocular Depth and Flow Estimation
Aug 25, 2022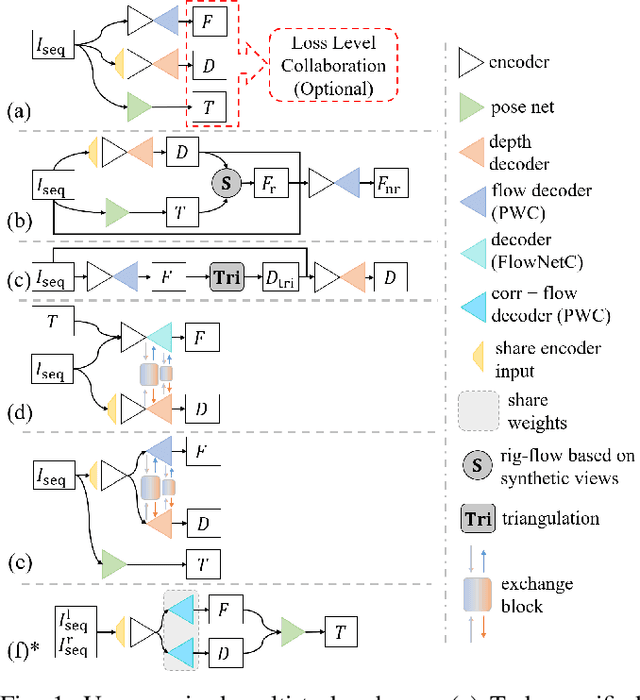
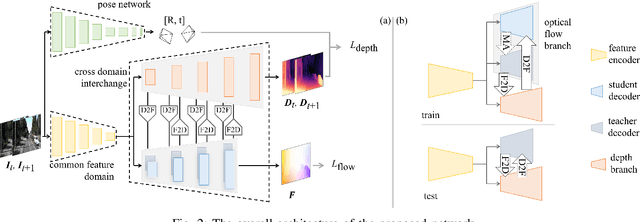
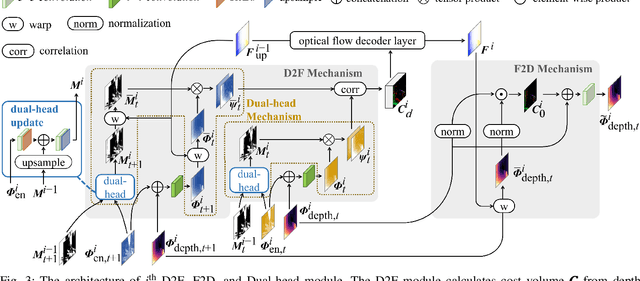
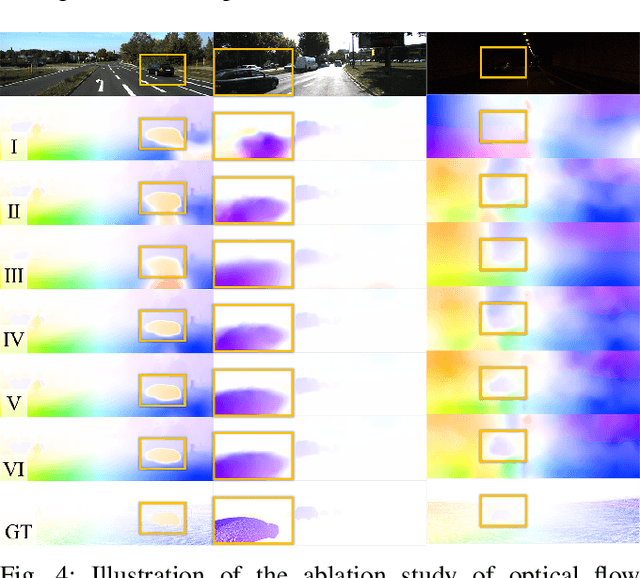
Accurate motion and depth recovery is important for many robot vision tasks including autonomous driving. Most previous studies have achieved cooperative multi-task interaction via either pre-defined loss functions or cross-domain prediction. This paper presents a multi-task scheme that achieves mutual assistance by means of our Flow to Depth (F2D), Depth to Flow (D2F), and Exponential Moving Average (EMA). F2D and D2F mechanisms enable multi-scale information integration between optical flow and depth domain based on differentiable shallow nets. A dual-head mechanism is used to predict optical flow for rigid and non-rigid motion based on a divide-and-conquer manner, which significantly improves the optical flow estimation performance. Furthermore, to make the prediction more robust and stable, EMA is used for our multi-task training. Experimental results on KITTI datasets show that our multi-task scheme outperforms other multi-task schemes and provide marked improvements on the prediction results.